TQDataSet 的 Filter 属性相比系统自带的数据表组件过滤表达式,进行了很大的增强,以方便用户使用。它支持以下操作符:
- 常见的比较操作:=、>、>=、<、<=、!=、<>,其中 != 和 <> 等价,代表不等于
- 模糊匹配操作:*、!*、like、nlike 分别对应 like、not like、like 和 not like 操作
- 列表操作符:in,notin 分别对应于 in 和 not in
- 正则表达式匹配符:~
- 逻辑关联操作:and 和 or ,分别代表与和或
- 括号操作符:( 和 )
TQDataSet 的 Filter 表达式扩展了 like 和 not like 操作的匹配模式,具体规则如下:
- _ : 单个任意字符
- * : 任意数量的任意字符
- % : 任意数量的任意字符,与 * 等价
- [字符列表] : 对应位置只能是列表中的字符
- [^字符列表] 或 [!字符列表] : 对应位置不能取列表中的字符
- \ : 符号转义
- \r : 换行符
- \n : 回车符
- \b : BELL(ASCII 码 7)
- \d : 数字(0-9,0-9)
- \D : 非数字
- \f : FEED(ASCII 码 12)
- \t : Tab(ASCII 码 9)
- \v : 垂直换行符( ASCII 码 11)
- \s : 空白字符(全角和半角空格、换行符、回车、Tab)
- \S : 非空白字符
- \uXXXX : 特定的Unicode字符,XXXX 为Unicode字符的十六进制编码
如果需要更复杂的匹配规则,请使用 ~ 操作符完成正则匹配。TQDataSet 的正则表达式的匹配模式可以使用类似 JavaScript 的字符串匹配模式完成,支持以下定义:
- i : 忽略大小写
- m : 多行匹配模式
- s : 单行匹配模式
- x : 扩展匹配模式,允许正则表达式包含额外的空白,新行或 Perl 样式的注释,所有这些都将被过滤掉
- A : 仅在内容开始或前一次匹配的右侧才能匹配成功
其它匹配符不受支持,而直接被忽略(如 /g )。和 JavaScript 的格式类似,正则匹配的模式的字符串以斜线开始,结束于斜线加上述模式字母的组合。下面是几个简单的例子:
Id ~ ‘/cc_\d\d$/i’ : 强制在匹配时忽略大小
Id ~’/cc_\d\d/is’ : 忽略大小写,并强制单行匹配
Filter 属性的格式和SQL标准的格式很像,但要过滤的字段名始终放在前面,而且暂时不支持内嵌函数。下面是一些有效的过滤的表达式例子:
Name like ‘王%’
Age>10
Name like ‘张_%’ and Age>10
(Name like ‘张%’) and (Age<30)
Name ~ ‘张.+’
下面是无效的表达式:
10<Age
Age>Max(Age)/2
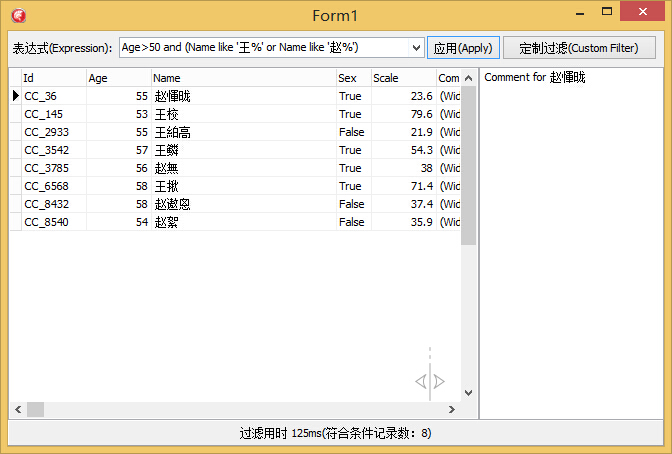
实际过滤效果截图: